萬戶OA售后服務與數字文化創意內容應用服務 構建高效協同辦公新生態
在當今數字化浪潮下,企業運營管理與文化創意內容生產正深度融合。萬戶OA作為一款成熟的企業協同辦公平臺,其完善的售后服務與前瞻性的數字文化創意內容應用服務,共同構成了支撐現代企業高效、創新發展的核心支柱。
一、 萬戶OA售后服務:穩定運行的堅實后盾
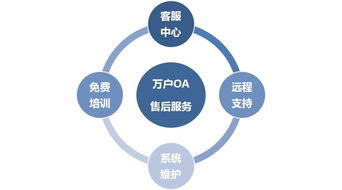
萬戶OA的售后服務并非簡單的故障響應,而是一個涵蓋全生命周期、旨在保障系統持續穩定與價值最大化的綜合服務體系。其主要內容與重要性體現在:
- 核心服務內容:
- 系統維護與技術支持:提供7×24小時在線或熱線支持,快速響應并解決系統使用中遇到的各類技術問題,確保辦公流程不中斷。
- BUG修復與補丁更新:持續監測系統運行,及時發布修復補丁和安全更新,堵住漏洞,保障系統安全性與穩定性。
- 數據備份與災難恢復:協助企業制定并執行數據備份策略,在發生意外時能快速恢復業務數據,將損失降至最低。
- 系統優化與性能調優:隨著企業規模擴大和業務變化,提供系統配置優化、性能瓶頸分析等服務,確保OA系統始終高效運行。
- 用戶培訓與知識傳遞:提供新功能培訓、操作指南更新及最佳實踐分享,幫助用戶不斷提升使用技能,充分發揮系統效能。
- 重要性與價值:
- 保障業務連續性:可靠的售后服務是企業日常辦公流程順暢進行的根本保障,避免因系統問題導致業務停滯。
- 保護投資回報:OA系統是企業的一項重要IT投資。優質的售后服務能延長系統生命周期,保護初始投資,并通過持續優化挖掘更大價值。
- 降低總體擁有成本(TCO):專業的維護能預防大故障的發生,減少緊急修復的高昂成本和業務中斷的隱性損失。
- 提升用戶滿意度與使用黏性:及時的支持和指導能顯著提升終端用戶的滿意度和工作效率,促進協同辦公文化的真正落地。
二、 數字文化創意內容應用服務:驅動創新與表達
在萬戶OA的生態中,數字文化創意內容應用服務是賦能企業文化建設、品牌傳播與內部創新的關鍵模塊。它超越了傳統OA的流程審批范疇,專注于內容的創意生產、管理、協作與分發。
- 核心服務內容:
- 創意內容創作與協作平臺:集成或提供豐富的模板、素材庫及簡易設計工具,支持團隊在線協同進行海報、視頻、H5、內部刊物等多媒體內容的創作。
- 數字內容資產管理(DAM):為企業建立統一的數字資產庫,對創意文案、圖片、視頻、品牌素材等進行分類、存儲、檢索和版本管理,提升內容復用率與品牌一致性。
- 全渠道內容分發與展示:將創作的創意內容無縫推送至OA門戶、知識社區、移動端、大屏展示終端等,營造濃厚的企業文化氛圍,助力內部宣傳與信息傳達。
- 互動與反饋機制:集成評論、點贊、投票、活動報名等互動功能,使內容傳播從單向發布變為雙向互動,激發組織活力與員工參與感。
- 數據分析與效果洞察:對內容閱讀量、互動率、傳播路徑等進行分析,量化文化內容的影響力,為后續創意策略提供數據支撐。
- 重要性與價值:
- 塑造與傳播企業文化:通過高質量的創意內容,生動形象地傳達企業價值觀、戰略目標和團隊精神,增強員工的歸屬感與認同感。
- 提升內部溝通效能:將枯燥的政策通知、培訓材料轉化為生動有趣的視覺化內容,大幅提升信息傳達的效率和員工的理解接受度。
- 激發組織創新活力:為員工提供了一個低門檻的創意表達與分享平臺,鼓勵創新思維,積累組織知識財富,打造學習型組織。
- 賦能品牌內部建設:統一管理品牌視覺資產,確保內部宣傳物料符合品牌規范,讓每位員工都成為品牌文化的理解者和傳播者。
- 適應新生代員工需求:契合年輕員工偏好數字化、視覺化、互動化溝通方式的趨勢,提升工作體驗和敬業度。
三、 協同融合:構建智慧辦公新范式
萬戶OA的售后服務與數字文化創意內容應用服務并非孤立存在,二者相輔相成,共同作用:
- 穩定支撐創意:強大的售后服務體系確保了創意內容應用平臺本身的穩定、安全與流暢運行,讓創意活動無后顧之憂。
- 服務賦能內容:在售后服務過程中,通過培訓和支持,引導用戶更好地利用創意內容工具,提升整體內容產出質量和應用水平。
- 一體化價值:兩者的結合,使得OA系統從一個單純的流程效率工具,升級為集高效運營、知識管理、文化建設和創新孵化于一體的智慧辦公中樞。它既確保了企業“肌體”(運營流程)的健康高效,也滋養了企業的“靈魂”(文化與創新)。
萬戶OA的售后服務是企業數字化基座穩固的“保障線”,而其數字文化創意內容應用服務則是驅動組織文化軟實力和創新力提升的“引擎線”。在數字化轉型深水區,企業選擇萬戶OA,不僅是引入一套工具,更是獲得一個由堅實服務護航、并能持續激發組織創意與活力的動態成長生態。這正是在激烈市場競爭中,構建核心優勢、實現可持續發展的關鍵所在。
如若轉載,請注明出處:http://www.xll66.cn/product/58.html
更新時間:2026-06-18 14:51:46